
快速排序
快速排序
xujiaojiao算法思路
通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
快速排序算法通过多次比较和交换来实现排序,其排序流程如下:
1、首先设定一个分界值,通过该分界值将数组分成左右两部分。
2、将大于或等于分界值的数据集中到数组右边,小于分界值的数据集中到数组的左边。此时,左边部分中各元素都小于或等于分界值,而右边部分中各元素都大于或等于分界值。
3、然后,左边和右边的数据可以独立排序。对于左侧的数组数据,又可以取一个分界值,将该部分数据分成左右两部分,同样在左边放置较小值,右边放置较大值。右侧的数组数据也可以做类似处理。
4、重复上述过程,可以看出,这是一个递归定义。通过递归将左侧部分排好序后,再递归排好右侧部分的顺序。当左、右两个部分各数据排序完成后,整个数组的排序也就完成了。
概括来说为 挖坑填数 + 分治法
动画展示

算法性能
时间复杂度
理想情况
如果足够理想,那我们期望每次都把数组都分成平均的两个部分,如果按照这样的理想情况分下去,我们最终能得到一个完全二叉树。如果排序 n 个数字,那么这个树的深度就是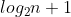
1 | T(n) ≤ 2T(n/2) + n,T(1) = 0 |
最坏情况
而在最坏的情况下,这个树是一个完全的斜树,只有左半边或者右半边。这时候我们的比较次数就变为
空间复杂度
原地排序
原地快排的空间占用是递归造成的栈空间的使用,最好情况下是递归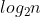 次,所以空间复杂度为
次,所以空间复杂度为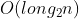 ,最坏情况下是递归 n-1 次,所以空间复杂度是
,最坏情况下是递归 n-1 次,所以空间复杂度是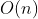 。
。
非原地排序
对于非原地排序,每次递归都要声明一个总数为 n 的额外空间,所以空间复杂度变为原地排序的 n 倍,即最好情况下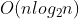 ,最差情况下
,最差情况下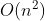
稳定性
不稳定。
代码实现
C++
1 | void quick_sort(vector<int> &q,int l,int r) { |
Python
1 | def quick_sort(self, nums: list[int], left: int, right: int): |
Java
1 | /* 快速排序 */ |


喜欢这篇文章的人也看了
评论
匿名评论隐私政策



